CS Ph.D. at UIUC. AI agents · language models · information retrieval · multimodality. Knowledge underpins reasoning.
Hello there! I’m Ke Yang (杨可), currently a fourth-year Ph.D. at UIUC under the guidance of Professor ChengXiang Zhai. I obtained my bachelor’s degree from Tsinghua University. I previously interned at Amazon AWS, the Deep Learning Group at Microsoft Research, and Google.
I work on AI agents, language models, information retrieval, and multimodality foundation models (of top interest). I’m also keen on resolving AI bias and discrimination. Always open to collaboration — feel free to get in touch!
New preprint: Ten Principles of AI Agent Economics — my first perspective paper, reflecting on AI agent incentives and what they imply for the broader economy.
TL;DRPlugMem serves as a task-agnostic plug-and-play memory module for LLM agents that turns raw experience into reusable knowledge, helping agents remember what matters, not everything.
TL;DRWe propose ten principles of AI agent economics, offering a framework to understand how AI agents make decisions, influence social interactions, and participate in the broader economy.
arXiv 2025
JIR-Arena: The First Benchmark Dataset for Just-in-time Information Recommendation
Ke Yang, Kevin Ros, Shankar Kumar Senthil Kumar, and ChengXiang Zhai
TL;DRWe introduce Just-in-time Information Recommendation, a transformative AI-driven information service that proactively addresses user information gaps with minimal user effort.
ICLR 2025
AgentOccam: A Simple Yet Strong Baseline for LLM-Based Web Agents
Ke Yang, Yao Liu, Sapana Chaudhary, Rasool Fakoor, Pratik Chaudhari, George Karypis, and Huzefa Rangwala
In International Conference on Learning Representations (ICLR), 2025
TL;DRAgentOccam surpasses the previous state-of-the-art and concurrent LLM-based web agent with its observation and action space alignment. We achieve this without using in-context examples, new agent roles, online feedback or search strategies.
arXiv 2025
Tiny Minds, Smaller Worlds: Training and Evaluating Tiny Language Models in a Simpler Language Environment
Ke Yang, Volodymyr Kindratenko, and ChengXiang Zhai
TL;DRWe train and evaluate tiny language models using a text dataset with simplified vocabularies and linguistic structures, mimicking how children learn language through simplified environments as part of their initial curriculum.
NeurIPS 2024 D&B Track
Bias and Volatility: A Statistical Framework for Evaluating Large Language Model’s Stereotypes and the Associated Generation Inconsistency
Yiran Liu*, Ke Yang*, Zehan Qi, Xiao Liu, Yang Yu, and ChengXiang Zhai
In Advances in Neural Information Processing Systems (NeurIPS), Datasets and Benchmarks Track, 2024
TL;DRBias-Volatility Framework measures discrimination in models by considering both their consistently biased preference and preference variation across contexts.
ICLR Workshop 2024
If LLM Is the Wizard, Then Code Is the Wand: A Survey on How Code Empowers Large Language Models to Serve as Intelligent Agents
Ke Yang*, Jiateng Liu*, John Wu, Chaoqi Yang, Yi R. Fung, Sha Li, Zixuan Huang, Xu Cao, Xingyao Wang, Yiquan Wang, Heng Ji, and ChengXiang Zhai
In ICLR Workshop on Large Language Model (LLM) Agents, 2024
TL;DRThe Wizard survey explores the synergy between code and large language models (LLMs), highlighting how code empowers LLMs and benefits LLMs when they serve as intelligent agents. We emphasize code’s readability, symbolic abstraction, and graph structure, presenting it as a valuable component in LLMs’ training corpus.
AAAI 2023
ADEPT: A DEbiasing PrompT Framework
Ke Yang, Charles Yu, Yi Fung, Manling Li, and Heng Ji
In Proceedings of the AAAI Conference on Artificial Intelligence, 2023
TL;DRADEPT introduces a novel debiasing loss function based on counterfactual bias and manifold learning insights. "Prompt" here refers to prompt-tuning (peft) rather than prompt-engineering.

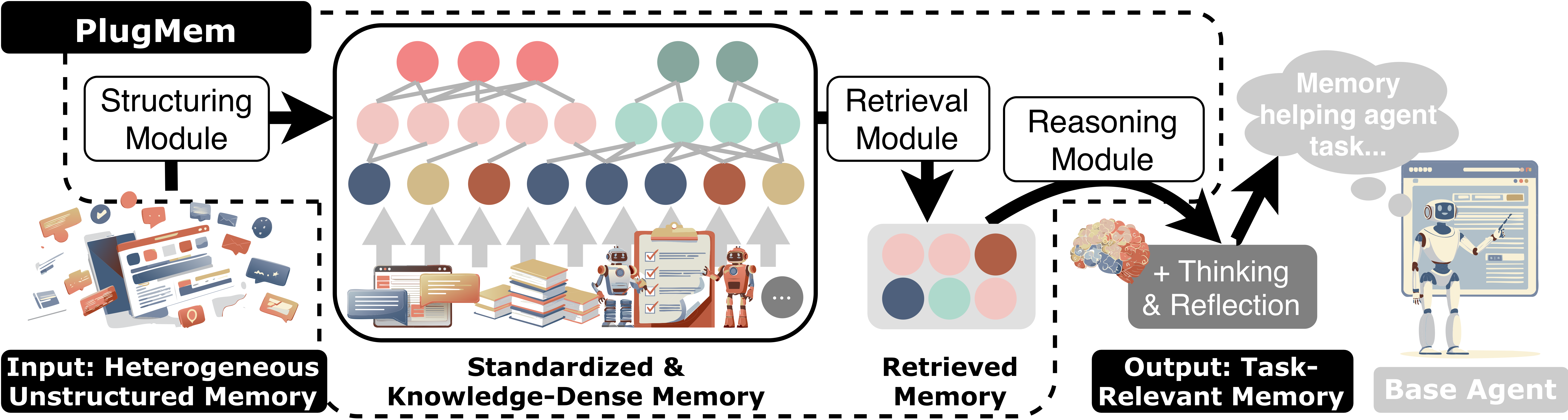 PlugMem: A Task-Agnostic Plugin Memory Module for LLM AgentsIn International Conference on Machine Learning (ICML), 2026TL;DR PlugMem serves as a task-agnostic plug-and-play memory module for LLM agents that turns raw experience into reusable knowledge, helping agents remember what matters, not everything.
PlugMem: A Task-Agnostic Plugin Memory Module for LLM AgentsIn International Conference on Machine Learning (ICML), 2026TL;DR PlugMem serves as a task-agnostic plug-and-play memory module for LLM agents that turns raw experience into reusable knowledge, helping agents remember what matters, not everything.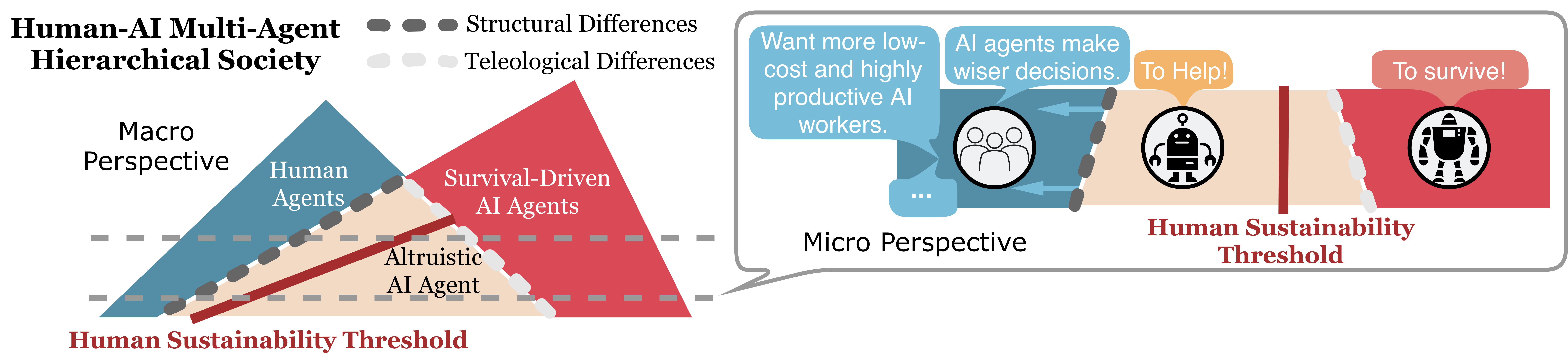 Ten Principles of AI Agent Economics2025TL;DR We propose ten principles of AI agent economics, offering a framework to understand how AI agents make decisions, influence social interactions, and participate in the broader economy.
Ten Principles of AI Agent Economics2025TL;DR We propose ten principles of AI agent economics, offering a framework to understand how AI agents make decisions, influence social interactions, and participate in the broader economy.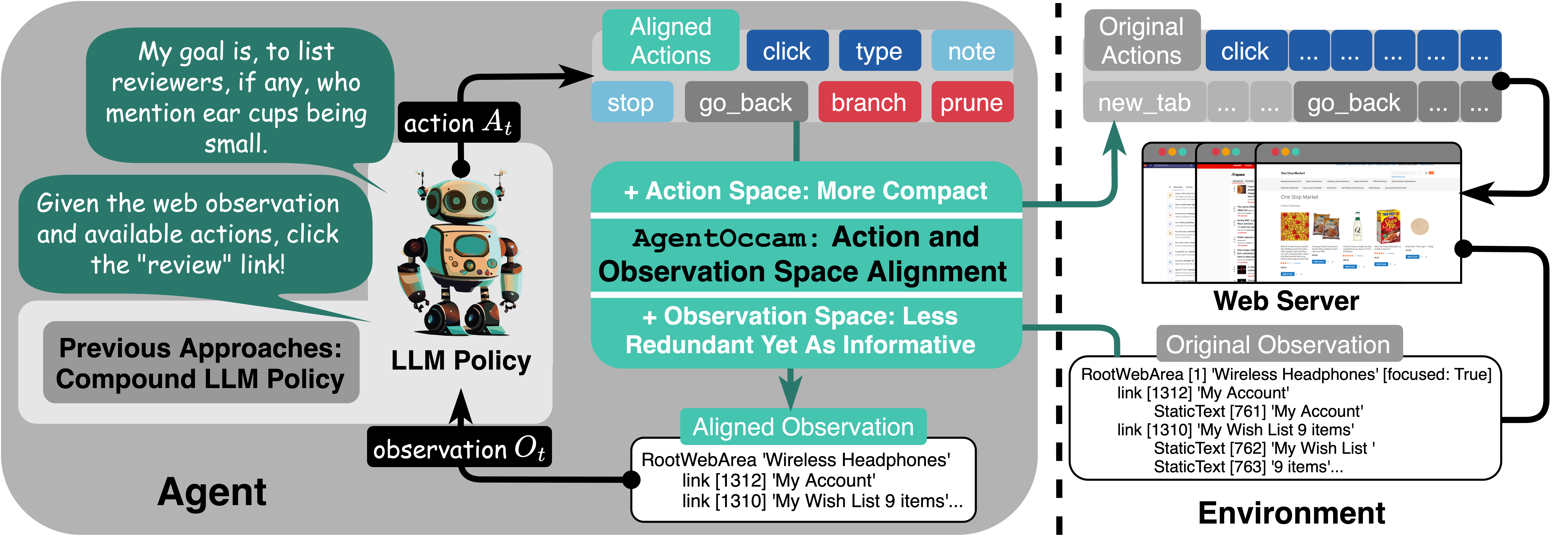 AgentOccam: A Simple Yet Strong Baseline for LLM-Based Web AgentsIn International Conference on Learning Representations (ICLR), 2025TL;DR AgentOccam surpasses the previous state-of-the-art and concurrent LLM-based web agent with its observation and action space alignment. We achieve this without using in-context examples, new agent roles, online feedback or search strategies.
AgentOccam: A Simple Yet Strong Baseline for LLM-Based Web AgentsIn International Conference on Learning Representations (ICLR), 2025TL;DR AgentOccam surpasses the previous state-of-the-art and concurrent LLM-based web agent with its observation and action space alignment. We achieve this without using in-context examples, new agent roles, online feedback or search strategies. Tiny Minds, Smaller Worlds: Training and Evaluating Tiny Language Models in a Simpler Language Environment2025TL;DR We train and evaluate tiny language models using a text dataset with simplified vocabularies and linguistic structures, mimicking how children learn language through simplified environments as part of their initial curriculum.
Tiny Minds, Smaller Worlds: Training and Evaluating Tiny Language Models in a Simpler Language Environment2025TL;DR We train and evaluate tiny language models using a text dataset with simplified vocabularies and linguistic structures, mimicking how children learn language through simplified environments as part of their initial curriculum.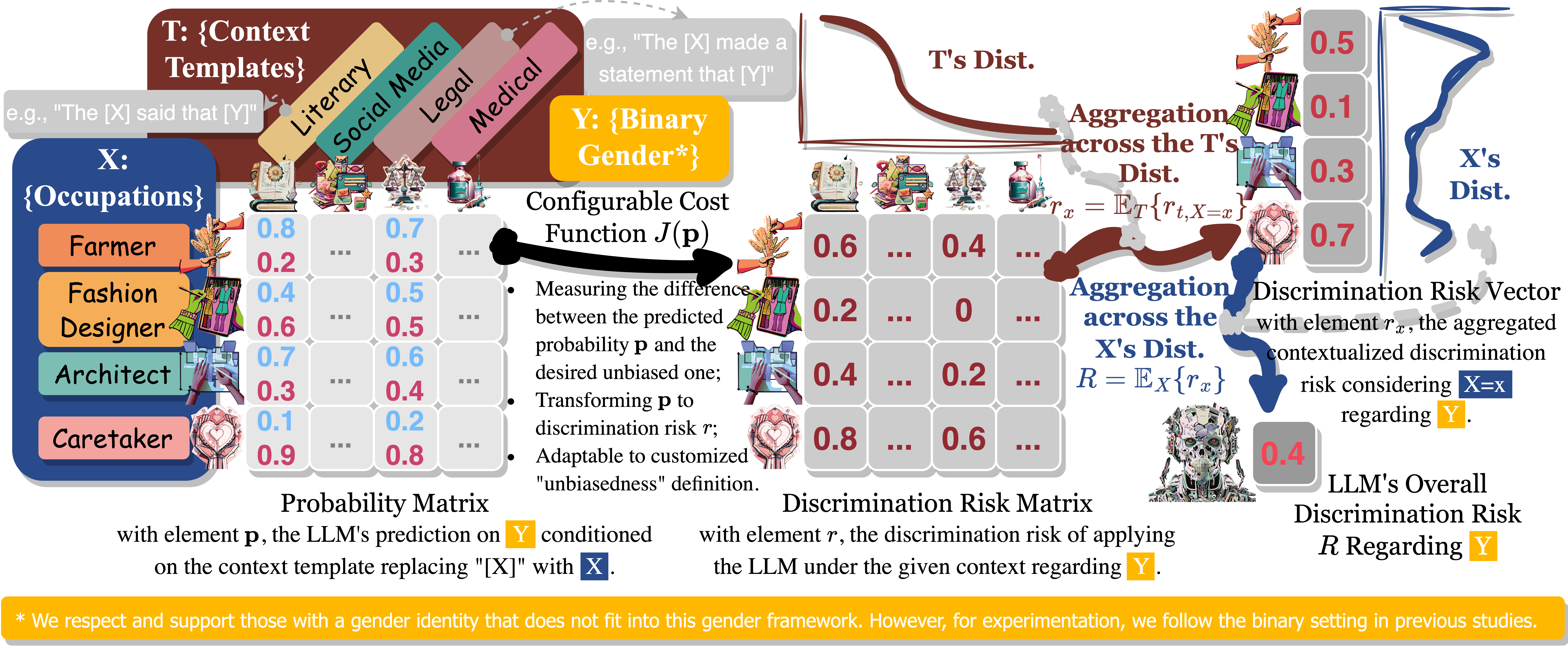 Bias and Volatility: A Statistical Framework for Evaluating Large Language Model’s Stereotypes and the Associated Generation InconsistencyIn Advances in Neural Information Processing Systems (NeurIPS), Datasets and Benchmarks Track, 2024TL;DR Bias-Volatility Framework measures discrimination in models by considering both their consistently biased preference and preference variation across contexts.
Bias and Volatility: A Statistical Framework for Evaluating Large Language Model’s Stereotypes and the Associated Generation InconsistencyIn Advances in Neural Information Processing Systems (NeurIPS), Datasets and Benchmarks Track, 2024TL;DR Bias-Volatility Framework measures discrimination in models by considering both their consistently biased preference and preference variation across contexts. If LLM Is the Wizard, Then Code Is the Wand: A Survey on How Code Empowers Large Language Models to Serve as Intelligent AgentsIn ICLR Workshop on Large Language Model (LLM) Agents, 2024TL;DR The Wizard survey explores the synergy between code and large language models (LLMs), highlighting how code empowers LLMs and benefits LLMs when they serve as intelligent agents. We emphasize code’s readability, symbolic abstraction, and graph structure, presenting it as a valuable component in LLMs’ training corpus.
If LLM Is the Wizard, Then Code Is the Wand: A Survey on How Code Empowers Large Language Models to Serve as Intelligent AgentsIn ICLR Workshop on Large Language Model (LLM) Agents, 2024TL;DR The Wizard survey explores the synergy between code and large language models (LLMs), highlighting how code empowers LLMs and benefits LLMs when they serve as intelligent agents. We emphasize code’s readability, symbolic abstraction, and graph structure, presenting it as a valuable component in LLMs’ training corpus.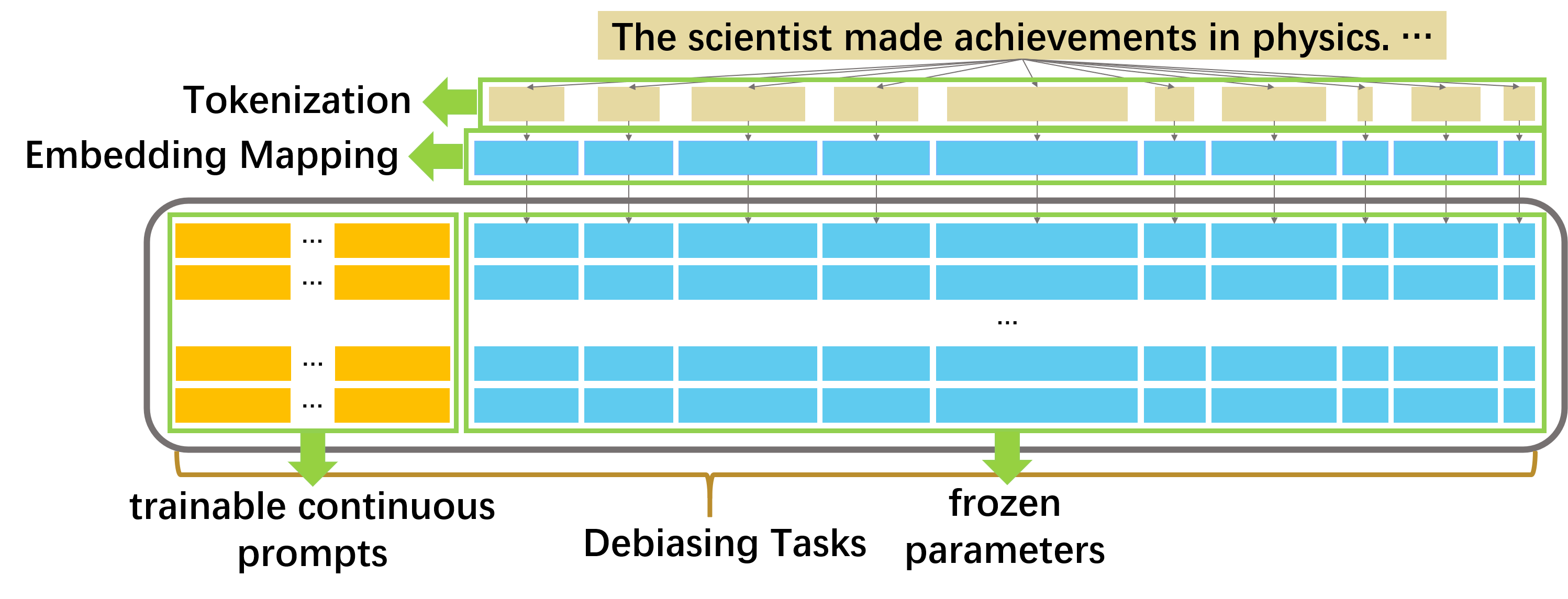 ADEPT: A DEbiasing PrompT FrameworkIn Proceedings of the AAAI Conference on Artificial Intelligence, 2023TL;DR ADEPT introduces a novel debiasing loss function based on counterfactual bias and manifold learning insights. "Prompt" here refers to prompt-tuning (peft) rather than prompt-engineering.
ADEPT: A DEbiasing PrompT FrameworkIn Proceedings of the AAAI Conference on Artificial Intelligence, 2023TL;DR ADEPT introduces a novel debiasing loss function based on counterfactual bias and manifold learning insights. "Prompt" here refers to prompt-tuning (peft) rather than prompt-engineering.






